

Reliable or Unreliable?
Over the past two decades and especially since the United States presidential election 2016 there is an increase in unreliable news content. The question which got and still gets asked is how can we know which is which. To find an answer I started at opensources which curates a list of online information sources. The websites listed range from credible news to misleading and outright fake.
The following post is part one in a series of four blog posts:
- collecting news content
- preprocessing data
- creating a keras model
- possible next step(s)
Collecting News Content
The source list (CSV file) which we can download from opensources has over 800 URLs. The first thing we want to do is to filter out all non-valid URLs.
for url in df['url']:
try:
code = urlopen('http://' + url).getcode()
except IOError:
df = df[df.url != url]
code = None
The resulting list we got back looks off. When we are looking at the categories and their number count we find that we need to do some cleaning:
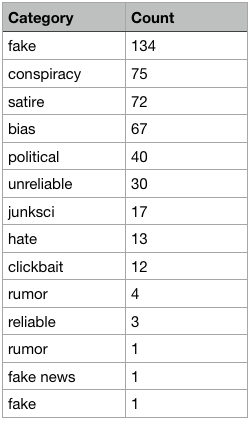
We have some oddly named categories and a meagre number of only 3 reliable URLs in the list. To address this imbalance, I added about 70 URLs I consider reliable (hopefully) of my own, which doesn’t balance the scale very much but at least pushes it into the right direction. Plus, let us see what and how much content we can scrape from the world wide web before we do something about the source list.
Web Scraping
There are several tools to get content from a website, scrapy and beautifulsoup are the two most popular tools probably out there. In both cases, we need to inspect the HTML code of a website. If you are interested to learn more about it, here is an excellent tutorial with tips and tricks using python.
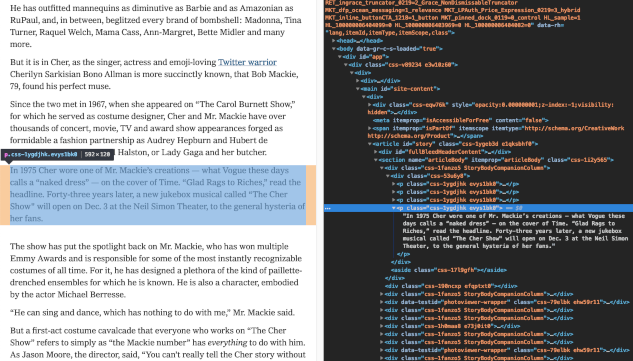
In any case, the primary challenge we are facing here is that every website has a different underlying architecture. To determine what the best options are I decided to look at NYTimes. As we can see in the image below, each paragraph is in its separate HTML tag. Collecting content only from the NYTimes website won’t be impossible, it is just exceedingly complicated, and neither of the mentioned tools won’t do it in the long run. If we are considering that we have over 500 labelled URLs, for the scope of this project, it is just not practical. There must be more straightforward ways to tackle this.
API
Luckily, the NYTimes offers an API to excess not only their archive but also search for the most current articles online. Even better, their developer site has a playground to sample what kind of results you can get and fine tune our query.
url = 'https://api.nytimes.com/svc/archive/v1/%s/%s.json?api-key=%s'
begin_year = 2017
end_year = 2018
with open('nytimes_data/archivesearch.json', 'w') as f:
with tqdm() as progress:
for year in range(begin_year, end_year + 1):
for month in range(1, 13):
try:
response = requests.get(url % (year, month, NYTIMES_TOKEN))
docs = response.json()['response']['docs']
except Exception:
print('Failed to get {}/{}'.format(year, month))
# There are two rate limits per API: 4,000 requests per day and 10 requests per minute.
# You should sleep 6 seconds between calls to avoid hitting the per minute rate limit.
time.sleep(6)
f.write(ujson.dumps(docs) + '\n')
The NYTimes search API gives us a wide range of options to query for data, starting with date range and fields like day_of_week, headline, subject etcetera, as well as news desk values like blogs, cars, fashion and many more.
Unfortunately, we only get the lead paragraph from our search which doesn’t help much if we are looking for the full articles. In the end, all we get is metadata, but that’s it.
webhose.io
There are a few websites which offer web scraping tools, for example import.io, webhose.io and dexi.io. We can find an extended list here. None are free, but some offer a free trial period and webhose.io is one of them which I ended up using.
Like the NYTimes, webhose.io also has a playground to fine tune our query with the main difference that you can see your search request in different coding languages like ruby or python. However, be aware, that you only have 1000 free requests.
Unfortunately, we can’t get access to all the URLs we have on our list. However, it gives us at least some data. We can also search through webhose.io’s archived data.
newsapi
The final tool I used is the python API from newsapi. The API is very similar to the NYTimes API in the way you write your code to collect the content we want. Like at the NYTimes we mainly get metadata. However, if we are willing to pay, we can get the full article content.
for source in news_sources:
# The source is a list similar to
# ['the-verge', 'the-wall-street-journal', 'the-washington-post', 'the-washington-times', 'time', 'usa-today', 'vice-news', 'wired']
#
# we should set the range to the maximum possible number based on the total results devided by page_size
# articles = newsapi.get_everything(sources=source, from_param=str(date), sort_by='relevancy', page_size=100)
# articles['totalResults'] // 100 + 1
for page in range(1, 3):
articles = newsapi.get_everything(sources=source, from_param=str(date), sort_by='relevancy', page_size=100, page=page)
try:
indexes = [i for i, v in enumerate(articles['articles']) if articles['articles'][i]['content'] is None]
for index in sorted(indexes, reverse=True):
del articles['articles'][index]
date_str = date.strftime("%Y%m%d")
filename = '_'.join([source, date_str])
json_file_name = get_json_file(filename, page, json_file_path)
with open(json_file_name, 'w+') as f:
f.write(ujson.dumps(articles) + '\n')
f.close()
except Exception as e:
print(e)
Conclusion
If we are serious about getting proper up-to-date news content, I believe that the API from newsapi is your API of choice. However, for the task ahead of us I choose to use the data I collected via webhose.io and may come back at a later time to update the project.
Additionally, there is an already polished and fairly large corpus we can use by Maciej Szpakowski.
Jupyter Notebook
Here is the notebook to that post.